I discovered a bug in a web app that I built a few years ago. It was difficult to debug because it only happened intermittently. As any programmer knows, issues that can’t be reproduced consistently (and locally) present the most pain. Ultimately, it was causing database records to be created in double – but only when certain conditions evaluated true in the app state.
I’ll get into the code fix in another post. Here, I’ll show you how I cleaned up the database. This application has over ten-thousand data records in production. The first thing I did before messing around was to export a back-up of the prod DB. That was only me being extra careful – I already have a nightly job that dumps the entire production database as a .sql file to an S3 bucket. Taking an export on the fly is easy through phpMyAdmin.
Step one is to identify duplicates and store them in a temporary table, using a GROUP BY clause. In MySQL (and most other SQL-based database systems),GROUP BY is used to group rows from a table based on one or more columns.
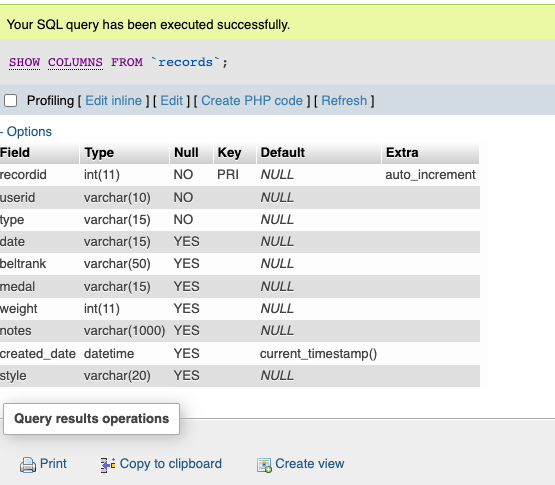
The duplicate rows that I am interested in have all identical values, except for their primary keys. I can group those rows (and put them into a new, temporary, table) by including all of the table columns names (except the primary key) in my SQL statement. You can list those names in phpMyAdmin with this command:
SHOW COLUMNS FROM `records`;
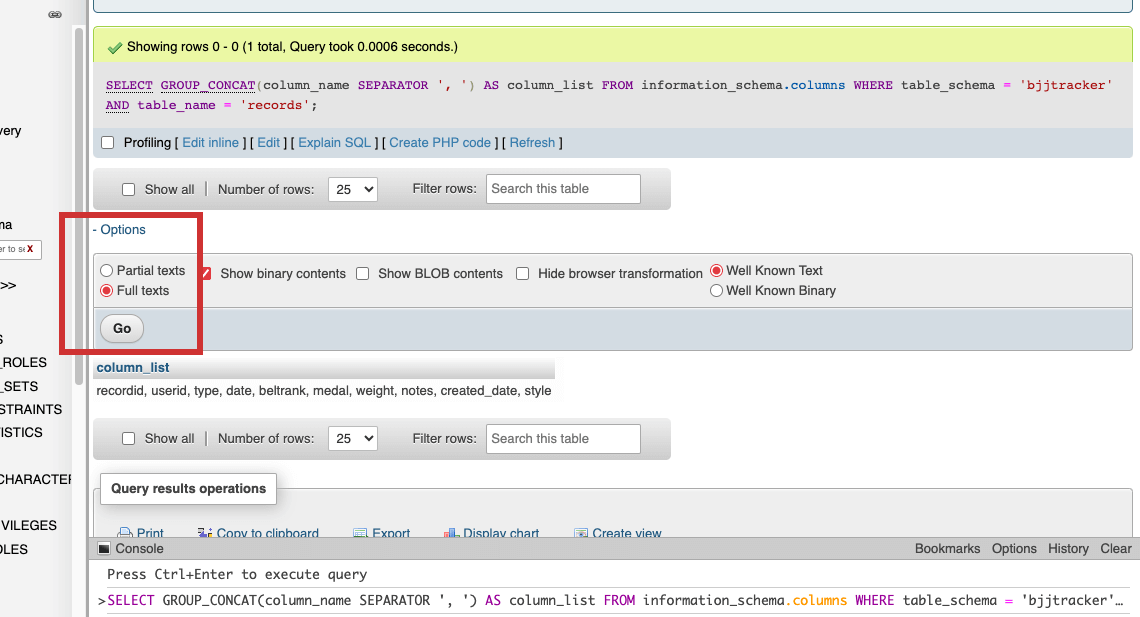
My tables have quite a few columns. Instead of copy/pasting each field name, I used SQL code to list them out together. This was possible by leveraging the INFORMATION_SCHEMA database, a special system database that provides metadata about the database server itself in MySQL. I could retrieve the column names and then concatenate them into a single string using the GROUP_CONCAT function:
SELECT GROUP_CONCAT(column_name SEPARATOR ', ') AS column_list FROM information_schema.columns WHERE table_schema = 'bjjtracker' AND table_name = 'records';
The result displayed as abbreviated until I selected “Full texts” from the options menu (highlighted below)
I could now copy/paste that column_list into my SQL statement. Remove the primary key field (usually the first one), or else no duplicates will be found (unless your use-case involves records having repeated primary key values, which is a less likely scenario).
CREATE TABLE TempTable AS SELECT userid, type, date, beltrank, medal, weight, notes, created_date, style -- List all columns except the primary key FROM `records` GROUP BY userid, type, date, beltrank, medal, weight, notes, created_date, style -- Group by all columns except the primary key HAVING COUNT(*) > 1; -- Indicates their is more than one record with exactly matching values
Now we have a new table that contains records that are duplicative in our original table. Step 2 is to delete the duplicates from the original table.
DELETE FROM `records`
WHERE (userid, type, date, beltrank, medal, weight, notes, created_date, style) IN (
SELECT userid, type, date, beltrank, medal, weight, notes, created_date, style
FROM TempTable
);
Don’t forget to delete that temporary table before you leave:
DROP TEMPORARY TABLE IF EXISTS TempTable;
Dealing with NULL values
On the first table I used this on, everything worked as expected. On a subsequent run against another table, zero rows were deleted even though my temp table contained duplicate records. I deduced that it was because of NULL values causing the comparison to not work as expected. I figured that I had to handle NULL values explicitly using the IS NULL condition on each field.
DELETE FROM recordsdetails
WHERE
(userid IS NULL OR userid,
recordid IS NULL OR recordid,
detailtype IS NULL OR detailtype,
technique IS NULL OR technique,
reps IS NULL OR reps,
partnername IS NULL OR partnername,
partnerrank IS NULL OR partnerrank,
pointsscored IS NULL OR pointsscored,
pointsgiven IS NULL OR pointsgiven,
taps IS NULL OR taps,
tappedout IS NULL OR tappedout,
result IS NULL OR result,
finish IS NULL OR finish,
created_date IS NULL OR created_date)
IN (
SELECT userid, recordid, detailtype, technique, reps, partnername, partnerrank, pointsscored, pointsgiven, taps, tappedout, result, finish, created_date
FROM TempTable
);
But yet, I still got zero rows being deleted. This time though, I was seeing a warning. It complained: “Warning: #1292 Truncated incorrect DOUBLE value”
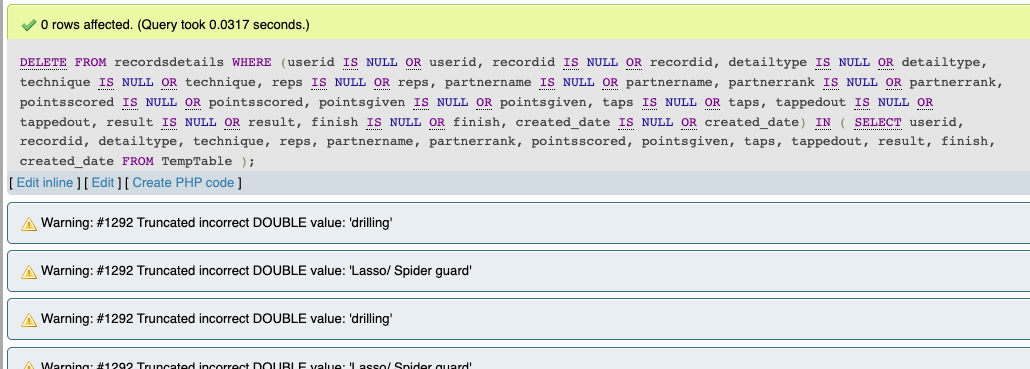
This suggests that there is a data type mismatch or issue in the comparison involving numeric and string values. My guess is that the IS NULL handling was causing type conversion issues. To remedy this, I wrote a more explicit query by combining the AND and OR conditions.
DELETE FROM recordsdetails
WHERE
(userid IS NULL OR userid IN (SELECT userid FROM TempTable)) AND
(recordid IS NULL OR recordid IN (SELECT recordid FROM TempTable)) AND
(detailtype IS NULL OR detailtype IN (SELECT detailtype FROM TempTable)) AND
(technique IS NULL OR technique IN (SELECT technique FROM TempTable)) AND
(reps IS NULL OR reps IN (SELECT reps FROM TempTable)) AND
(partnername IS NULL OR partnername IN (SELECT partnername FROM TempTable)) AND
(partnerrank IS NULL OR partnerrank IN (SELECT partnerrank FROM TempTable)) AND
(pointsscored IS NULL OR pointsscored IN (SELECT pointsscored FROM TempTable)) AND
(pointsgiven IS NULL OR pointsgiven IN (SELECT pointsgiven FROM TempTable)) AND
(taps IS NULL OR taps IN (SELECT taps FROM TempTable)) AND
(tappedout IS NULL OR tappedout IN (SELECT tappedout FROM TempTable)) AND
(result IS NULL OR result IN (SELECT result FROM TempTable)) AND
(finish IS NULL OR finish IN (SELECT finish FROM TempTable)) AND
(created_date IS NULL OR created_date IN (SELECT created_date FROM TempTable));
That worked! With a cleaned database, it was time to figure out what was causing the bug in the first place, and to fix the problem.
Clones in quiet dance; Copies of our code converge; Echoes of our souls;