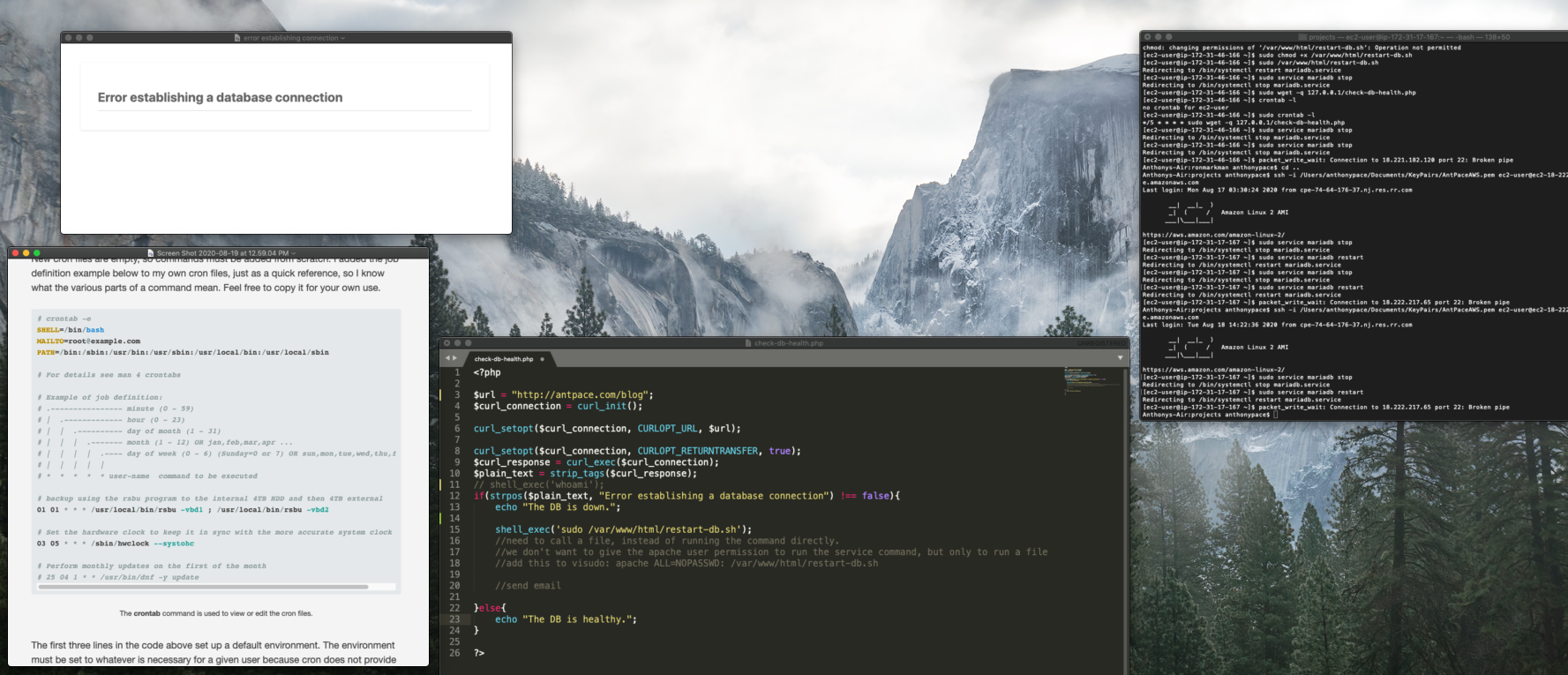
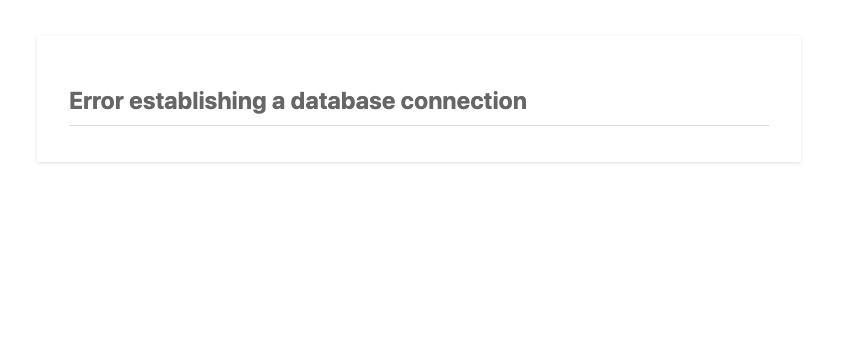
A crashed database is a problem I’ve encountered across multiple WordPress websites. When trying to load the site you’re faced with a dreaded “Error establishing a database connection” message. Restarting the DB service usually clears things up. But, sometimes it won’t restart at all – which is why I started automating nightly data dumps to an S3 bucket.
Recently, one particular site kept going down unusually often. I assumed it was happening due to low computing resources on the EC2 t3.micro instance. I decide to spin up a a new box with more RAM (t3.small) and migrate the entire WordPress setup.
Since I couldn’t be sure of what was causing the issue, I needed a way to monitor the health of my WordPress websites. I decided to write code that would periodically ping the site, and if it is down send an email alert and attempt to restart the database.
The first challenge was determining the status of the database. Even if it crashed, my site would still return a 200 OK response. I figured I could use cURL to get the homepage content, and then strip out any HTML tags to check the text output. If the text did match the error message, I could take further action.
Next, I needed to programmatically restart MySql. This is the command I run to do it manually: sudo service mariadb restart
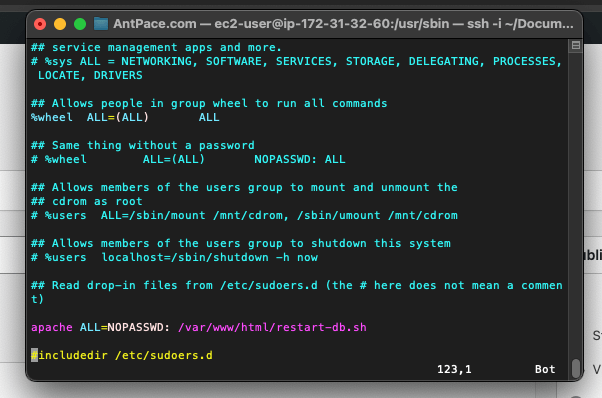
After doing some research, I found that I could use shell_exec() to run it from my PHP code. Unfortunately, Apache wouldn’t let the (non-password using) web server user execute that without special authorization. I moved that command to its own restart-db.sh file, and allowed my code to run it by adding this to the visudo file: apache ALL=NOPASSWD: /var/www/html/restart-db.sh
My visudo file was located at /usr/sbin/visudo. It is a tool found on most Linux systems to safely update the /etc/sudoers file, which is the configuration file for the sudo command. To edit this file, I don’t open it in vim like I would with other editable files. Instead, I run the file as its own command: sudo visudo. Once it is open, you can press the i key to enter “insert” mode. It is considered “safe” because it edits the sudoers file following a strict procedure.
I also needed to make the file executable by adjusting permissions: sudo chmod +x /var/www/html/restart-db.sh
Once those pieces were configured, my code would work:
<?php
$url = "https://www.antpace.com/blog/";
$curl_connection = curl_init();
curl_setopt($curl_connection, CURLOPT_URL, $url);
curl_setopt($curl_connection, CURLOPT_RETURNTRANSFER, true);
$curl_response = curl_exec($curl_connection);
$plain_text = strip_tags($curl_response);
if(strpos($plain_text, "Error establishing a database connection") !== false){
echo "The DB is down.";
//restart the database
shell_exec('sudo /var/www/html/restart-db.sh');
//send notification email
include 'send-email.php';
send_email();
}else{
echo "The DB is healthy.";
}
?>
You can read more about how to send a notification email in another post that I wrote on this blog.
The contents of restart-db.sh looks like this:
#!/bin/bash sudo service mariadb restart
Create the cron job
A cron job is a scheduled task in Linux that runs at set times. For my PHP code to effectively monitor the health of the database, it needs to run often. I decided to execute it every five minutes. Below are three shell commands to create a cron job.
The first creates the cron file for the root user:
sudo touch /var/spool/cron/root
The next appends my cron command to that file:
echo "*/5 * * * * sudo wget -q https://www.antpace.com/check-db-health.php" | sudo tee -a /var/spool/cron/root
And, the last sets the cron software to listen for that file:
sudo crontab /var/spool/cron/root
Alternatively, you can create, edit, and set the cron file directly by running sudo crontab -e . The contents of the cron file can be confirmed by running sudo crontab -l .
Pro-tip: If your WordPress site does continually crash, you probably do need to upgrade to an instance with more RAM. Also, consider using RDS for the database.
Update
I previously used the localhost loop back address in my cron file: */5 * * * * sudo wget -q 127.0.0.1/check-db-health.php. After setting up 301 redirects to prevent traffic from hitting my public DNS, that stopped working. It is more reliable to use an explicit domain name URL: */5 * * * * sudo wget -q https://www.antpace.com/check-db-health.php