It all started with a client text message that was hard to miss — their website was suddenly showing a GoDaddy “parked” page. This unexpected hiccup was more than just a minor inconvenience; it was a full-blown business disruption for my client.
The Challenge
When the client reached out, he was understandably frustrated. His website, which was supposed to be active and processing sign-ups, was inactive, displaying a message typically associated with unconfigured or newly registered domains. This was particularly perplexing as the site had been running smoothly just days before.
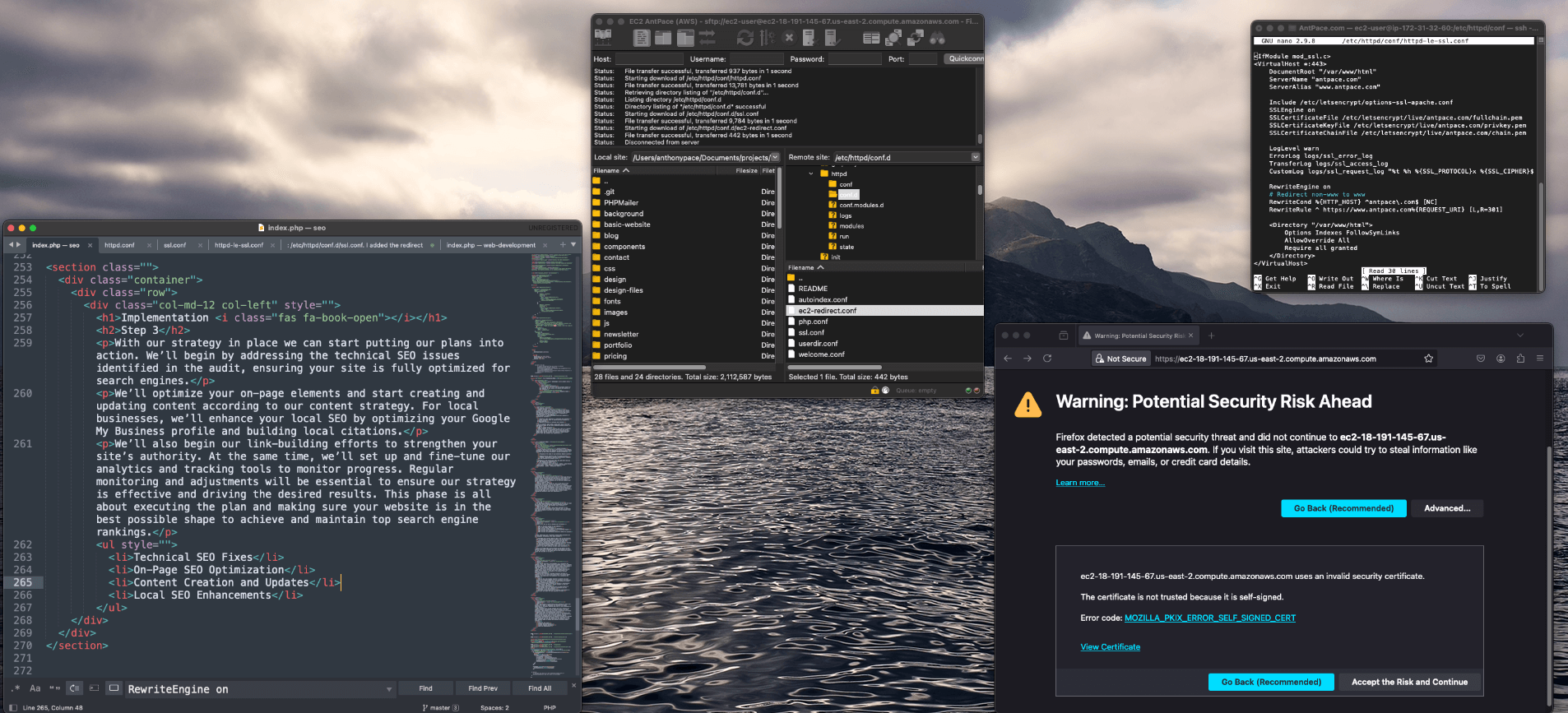
My first step was to verify the DNS settings. A parked domain page usually indicates issues with domain pointing, possibly due to changes in DNS or hosting services. The client told me he had tried to create a subdomain through his domain registrar, GoDaddy. It turned out that his domain’s name servers pointed to his web hosting company, DreamHost. Making DNS changes directly in GoDaddy led to a change in the domain’s nameserver records so that it became managed by GoDaddy directly, removing any reference to the web hosting package where the site actually lived.
The Solution
After identifying the mismatch, the next step was clear but not simple—access the DreamHost account to find the correct nameserver value to point the domain to. However, the client didn’t have the DreamHost login credentials readily available, which added another layer to our challenge.
Using SecurityTrails, I conducted a DNS history check. This not only confirmed that the name servers were indeed pointing to DreamHost but also provided a clear historical view of the DNS changes over time. I was able to copy and paste the name server values from the history log. Subsequently, we were able to recover access to the DreamHost account by going through account recovery processes, which involved verifying the client’s identity and ownership of the domain.
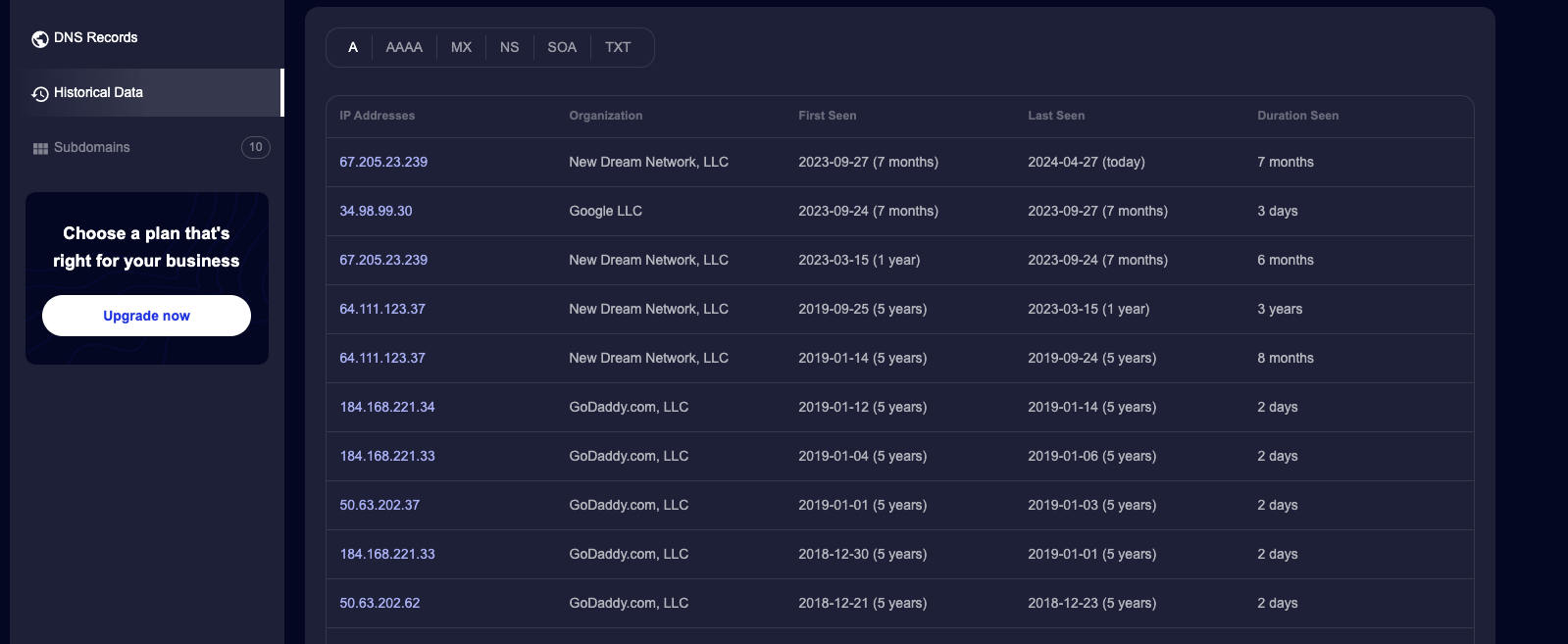
Once we regained access, I immediately updated the DNS records to ensure they correctly pointed to the client’s active web server. This change effectively removed the parked page error, restoring the site’s functionality.
Conclusion
This scenario underscored the critical importance of keeping domain and hosting details organized and accessible. It also highlighted how easy it is for essential information to become overlooked, especially when multiple service providers are involved over the years. Effective disaster recovery strategies are crucial for quickly restoring operations in the event of a service disruption, whether caused by human error, technical failures, or external threats.
With the website back up and running, and the domain correctly configured, the client was relieved and could focus on his business again. For me, it reinforced a key aspect of my work: solving complex tech puzzles not only requires technical know-how but also an investigative approach to untangle the often convoluted web of digital assets. My role transcends building websites—it’s about ensuring they continue to serve their purpose, even when unexpected disruptions occur.
While my tagline says, “I can build your website,” days like these remind me it should also include, “and I can rescue it too.” This experience serves as a testament to the value of professional web management, especially in a world where digital presence is synonymous with business viability.